检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的极速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox
2026年6月,统计与大数据研究院2024级博士生林俊一(第一作者)、2025届博士毕业生李梦雨(共同第一作者)、孟澄助理教授(通讯作者)与南开大学周永道教授(通讯作者)合作的论文“Sparsification Subsampling for Partial Least Squares Regression”已被国际统计领域重要学术期刊《Journal of Computational and Graphical Statistics》接收发表。

研究背景
偏最小二乘回归(Partial Least Squares,简称 PLS)是一类重要的多元统计方法,广泛用于降维、多响应变量回归和多分类任务。它通过构造与响应变量高度相关的低维潜变量,在高维数据和多重共线性场景下具有较强适用性。
随着数据规模不断扩大,PLS 在实际应用中面临明显的计算压力。传统算法需要围绕预测变量和响应变量反复进行大规模矩阵运算,当样本量很大时,计算成本会成为限制其应用的重要因素。已有在线学习、随机批量学习和行子抽样等方法能够在一定程度上加速 PLS,但如何在保证精度的同时系统降低计算复杂度,仍有进一步研究空间。
方法简介
与按样本行抽样不同,元素级子抽样直接在观测矩阵的元素层面进行选择。这样既能减少参与计算的数据量,又能尽可能保留每个样本中的关键信息,避免未被抽中的整行观测完全丢失。围绕上述问题,论文提出了 Sparsification Subsampling for Partial Least Squares(Spar-PLS)。该方法的核心思想是:先对预测矩阵进行元素级稀疏化,得到一个能够代表原始数据信息的稀疏草图,再将该草图引入 PLS 的核心迭代过程,从而减少大规模矩阵乘法带来的计算负担。
在抽样概率设计上,论文从近似矩阵乘法的角度出发,证明了稀疏化近似具有无偏性,并给出了能够降低近似误差的元素级抽样概率。进一步地,论文将这一最优性推广到带投影结构的情形,为 PLS 中关键信息矩阵的稀疏估计提供了理论依据。
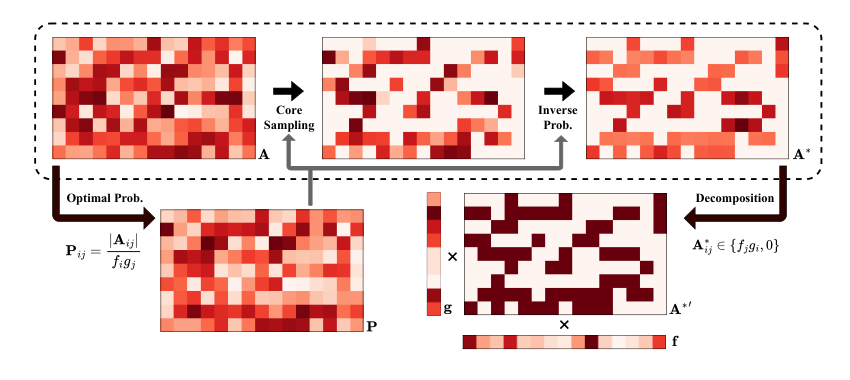
稀疏化子抽样流程示意:根据元素重要性构造稀疏草图,并通过逆概率加权保持矩阵近似的无偏性。
在算法实现上,Spar-PLS 将核心元素估计思想引入 PLS 回归,并结合经典核化 PLS 框架,避免在每轮迭代中直接更新大规模残差矩阵。由此,算法能够把主要计算集中在稀疏草图相关的矩阵运算上,显著弱化样本量对运行时间的影响。
实验结果
论文通过数值模拟和真实数据实验验证了 Spar-PLS 的有效性。在数值模拟中,Spar-PLS 与全样本 PLS 以及多种经典行抽样方法进行比较。结果表明,Spar-PLS 在较低采样比例下仍能保持良好的估计与预测性能,整体优于现有行抽样策略。在波浪能转换器数据集上的真实数据分析中,Spar-PLS 同样表现出稳定优势。该方法在多数实验设置下取得更低的预测误差,并实现约 80% 至 90% 的运行时间提升,进一步说明其在大规模多响应回归任务中的实用价值。
总体而言,Spar-PLS 通过元素级稀疏化子抽样,将矩阵稀疏化思想与 PLS 回归有效结合,在保持估计精度和预测能力的同时显著提升计算效率。该研究为大规模多响应回归、高维监督降维以及具有空间结构的能量输出建模等任务提供了一种有效的 PLS 加速方案。
作者简介

林俊一,统计与大数据研究院2024级博士生,主要研究方向为最优运输、生成模型、数据压缩、多模态对齐等。曾在 JCGS、ICLR 等国际知名统计和机器学习期刊或会议上发表论文。曾入选全国工业统计学教学研究会青年统计学家协会年会博士生论坛、茆诗松统计教育博士生论坛并作口头报告。
